What is Data Science?

Data scientist roles are often one of the most highly-paid and highly-rewarding jobs out there. Glassdoor has cited data scientist at the #1 position for most-satisfying job in the United States. With the explosive growth of unstructured data, there has never been a greater need for data scientists.
This has prompted a wave of questioning about how to be a data scientist, with upwards of 600 people a month searching for that on Google.
IBM predicts demand for data scientists will increase 28% by 2020. Data science roles are among LinkedIn’s fastest and most growing emerging fields with about 650% growth since 2012.
Data science combines statistical knowledge, programming chops and domain expertise/communication skills. You’ll work on dealing with large amounts of data and get as much insight at scale as you can.
Job Prerequisites
To become a data scientist, you have to have a solid understanding of statistics, mathematics and the theory behind different algorithms.
You also have to have enough programming chops, usually in a language such as Python or R to iterate with data science models.
You also have to be able to communicate your findings to top executives. You need to have enough domain expertise to understand your data and the implications of it.
Typically, most roles will need advanced degrees and programming experience. STEM degrees are preferred. However, some companies will hire undergraduates straight from school — and advanced degrees, while preferred, are not a hard prerequisite. You can do data science without a PhD or even a Master’s degree.
Data Science Salary

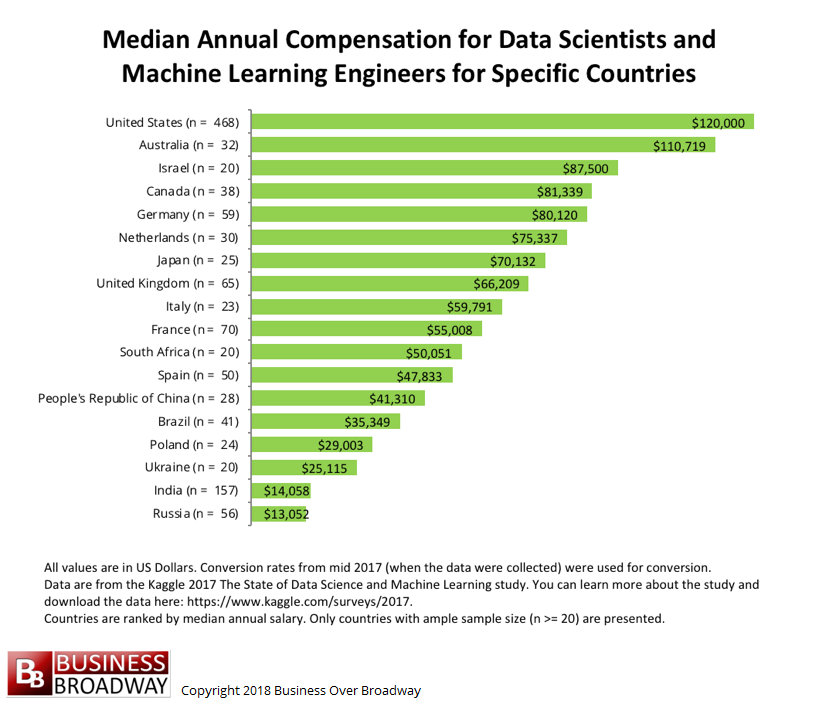
Based on a Kaggle survey, data scientists and the adjacent field of machine learning engineers earn the highest median salary ($120,000 USD) in the United States of America. Australia closely follows at about $110,000 USD. Other countries fall swiftly down the median, with data scientists earning close to $15,000 USD in both Russia and India.
While it’s clear that you can earn a lot being a data scientist, it’s also true that there are nuances.
The division in the United States makes this clear. States like California and New York have the highest volume of data science jobs. California data scientists average about $140,000 USD in yearly salary. Washington and New York State follow up in the $115,000 USD to $120,000 USD range. New Jersey, Maryland, and North Carolina are around there as well.
California is home to Silicon Valley and the growing startups in San Francisco. Washington state headquarters both Microsoft and Amazon. New York state and adjacent states like New Jersey host large vibrant startup ecosystems including Silicon Alley. While all these figures need to be adjusted for cost of living (different states like Kansas come first due to their low cost of living in another analysis), they show a key tenet of raw data science salaries: to earn as much as possible, you’ll have to go to where data is most valuable.
Factors That Increase Your Data Science Salary

I wrote this handy guide from Springboard on factors that increase your data science salary after doing some research. The most important ones are the data science tools you have experience with, the industry you work in, the location you choose to work in (as discussed above), the data science role you choose, your experience and degrees, and the individual negotiation for each salary.
Understanding big data tools like Spark and data visualization tools like D3.js, a powerful and advanced custom library for strong visualization might increase your yearly salary by between $8,000 USD and $15,000 USD.
It’s not just data science in general that drives your salary, it’s also the individual components you’re familiar with. Premiums are paid for data scientists who know how to handle large amounts of data in a distributed fashion, and those who can work with powerful data visualization libraries.
If you have up to 15 data science tools mastered, it can increase your salary about $30,000 USD.
You’ll also want to work in an industry that has access to a lot of valuable data. This tends to be software or social media companies who pay the highest for data scientists (think Facebook or Google).
You’ll want to make sure you’re working as a data scientist or data engineer, not a data analyst. Most intro-level roles in the data space are data analyst roles. It will affect your future salary if you stay in data analyst roles or only apply to them.
As discussed, your location is key as well. If you want the absolutely highest raw salary, you’ll have to move to the United States, and you’re likely going to be working in one of the tech hubs there (either San Francisco/Silicon Valley, New York City, or the DC area). However, you should note that the amount of salary you can gain on location, while high, may not be as high as other factors that don’t need you to move.
Finally, your level of experience can make a dramatic difference. Having ten or more years of experience can add around $30,000 USD to your yearly salary as a data scientist. And while degrees might not be a hard prerequisite, those with advanced degrees do tend to earn more as data scientists.
Data Science Curriculum/Checklist

First, you’ll want to start with enough programming knowledge so you can play around with the different concepts and libraries. In practice, a lot of the statistics and mathematics is abstracted away by different programming libraries. It’s best to learn some of the basics of statistics and programming at the same time. If you had to focus on one area, start with the programming practice.
Most machine learning and data science libraries (including Pandas, Numpy and scikit-learn, the mainstays of data science) are compiled in Python. You’ll want to start there, and work with Anaconda so you can manage different packages and dependencies. Once you’re in, you can find different courses to practice your Python programming, and practice live in the Jupyter Notebook offered, which is an intuitive and easy-to-access editor for code that can be run locally and uploaded or given version control quite easily by hooking it up with Git and a Github account.
Here’s the documentation for how to get started with Anaconda and Jupyter notebook. The following post summarizes different ways of working with Jupyter notebooks and version control. Finally, this post from freeCodeCamp explains Git and the importance of version control.
While you can work on Jupyter Notebook in a local context by yourself and seldom do anything but upload your finished experiments and files to Github (something I’ve often done), building in the habit of working with version control is a great practice.
It’s the default method of collaboration between different programmers, who must ensure that code doesn’t conflict — so if you want to work on a data science team, or any software team for that matter, it’s always good to start with good habits.
You’ll also want to use version control to revert back in case something goes wrong and to maintain a steady thread of progress.
Programming
R vs Python
A large part of the data science ecosystem debate is whether or not to use R or Python as an intro-level programming language to get started. In this article for The Next Web, I wrote that it was ideal to know both. Realistically, if you had to choose, I would go with Python. We’ll start there, but I’ll add some R resources in case.
R
Codecademy can help you practice your R skills before you start applying it to data science use cases.
Introduction to R for Data Science
This interactive course is given by Microsoft on the edX platform, and is completely free to access. You will need to pay $99 USD if you want to have a verified certificate on your profile.
Python
49 Essential Resources to Learn Python
I wrote this list of resources to learn Python, going from beginner to advanced. Go through and pick out the resources that are data science and machine learning-specific.
Learning Python: From Zero to Hero
A text-based tutorial that summarizes the basics of Python. It will get you from knowing zero to Python hero.
Python Tutorial: Learn Python For Free | Codecademy
Codecademy was how I learned Python. Working through the interactive course modules will help you move through and learn by doing and practicing.
SQL
21 of the Best Free Resources to Learn SQL
You’ll want to practice your SQL as well if you’re looking to become a data scientist. A large amount of data is still held in structured SQL tables. Practicing with SQL will help you extract that data and work with it.
SQLZoo works partly as a Wiki, partly as a set of interactive exercises. I use this to sharpen my SQL skills when I need to practice.
Pandas
Pandas dataframes are the default unit of data wrangling in data science work. Pandas allows you to organize your data in a tabular, structural fashion similar to a SQL table or an Excel spreadsheet. It also allows you to use Python to programmatically treat data.
This handy guide goes over the Pandas library and different things you can do with it from grouping to aggregation functions. It’s a handy interactive guide to Pandas — and it’s how I first started getting familiar with the library and data science in general.
A Comprehensive Guide to Data Wrangling
This guide helps define data wrangling, why it’s important, and introduces a few new functions and situations in Pandas to get you comfortable with it.
Statistics
Once you’re able to source data, you’ll need the statistical ability to be able to draw insight from the data you’ve collected.
As you’re learning the programming you need, you need to be able to understand statistics to manipulate data, understand it, and evaluate different models. This often involves at least a basic understanding of probability, frequentist and Bayesian statistics.
Statistics and Probability: KhanAcademy
This interactive video-filled course will help you catch up on frequentist statistics, confidence intervals, p-values, and more. It’ll serve as a refresher if you’ve encountered these concepts in university, and a learning opportunity if you haven’t.
A Concrete Introduction to Probability by Peter Norvig
This iPython Notebook allows you to directly work with probability concepts in your own version of Jupyter Notebook should you desire. It expresses probability ideas in very readable Python code, helping to combine both your programming practice and statistics knowledge.
Bayes’s Theorem: A Visual Introduction
This post introduces Bayesian theory with a lot of visualizations. It can take the visualizations to really crystalize Bayesian thinking, especially since it involves a lot of segmentation on probability.
Introduction to Bayesian Inference
This tutorial uses a Python library to explain Bayesian reasoning through a model of click-throughs on ads. Use it to understand Bayesian inference in practice.
Mathematics
Once you’re done with the statistics, it can be good to understand some of the mathematics behind data science and machine learning even if most of the detail is not something you’ll confront everyday given how abstracted away most of the math is.
The Mathematics of Machine Learning
The Towards Data Science article sums up the categories of mathematics you need to learn as well as links to different courses.
Mathematics of Machine Learning
This book is offered as a free PDF, covering several sections of machine learning math in detail from analytic geometry to vector calculus.
Machine Learning
Now that you’ve refreshed or embraced statistics and programming concepts, it’s time to take it all together and learn the machine learning algorithms you can use on your data.
A Tour of Machine Learning Algorithms
Starting with foundational concepts in machine learning such as the difference between supervised and unsupervised learning (and semi-supervised) we can then drill down into the different categories of machine learning algorithms and broadly see how the logic works with a set of visualizations.
10 Machine Learning Algorithms You Need To Know
This Towards Data Science Medium post then dives a bit deeper into ten specific machine learning algorithms, giving code implementations of a few so you can see them in practice on data.
Data Modelling/Evaluation
After all the work on different algorithms, it’s time to refresh what makes for a good data model. How do you know if your model is working? This section of resources will help you put that together.
Part-4 Data Science Methodology From Modelling to Evaluation
The article summarizes the data science methodology. In this section, it focuses on how evaluating your model fits with the broader work of machine learning and data science.
Various ways to evaluate a machine learning model’s performance
The following tutorial includes a breakdown of evaluation metrics beyond accuracy such as the confusion matrix and the ROC curve.
Data Visualization
Matplotlib is the default data visualization library embedded in Python, and something designed to be used off-the-bat with Pandas. You can use its visualizations to get a quick sense of the data yourself without needing to export it. This guide goes over the basics of Matplotlib and how it’s constructed.
Seaborn is a Python library that provides more compelling data visualizations than the default Matplotlib library. Use this tutorial to get familiar with it.
Intro to D3.js with ten examples
This D3.js introduction helps get you started with the powerful JavaScript library. The related chart collection helps collect tons of examples of different charts you can use to visualize your data in R, Python and more.
Datasets to Practice With
Kaggle, the online data science competition platform, offers a variety of datasets you can use to practice your data science skills. The datasets feature ranking and comments so you can follow the most trending datasets. You can study what others have done with them as inspiration for your own projects.
19 Free Public Data Sets for Your Data Science Project
The link above is a list of 19 free, public datasets ranging from United States census data to FBI crime data.
A Github repository that hosts a wide variety of open, public databases. They are organized by their domain. This is a great definitive resource for free datasets.
This website hosts datasets, some of them quite large, hosted on IPFS (the interplanetary file system). This is a distributed, decentralized protocol of storing data that goes beyond HTTP’s standard server-client relationships. In theory, this means that datasets downloaded through IPFS might be faster to get. After all, you’ll be working with a swarm of hosts rather than just a single one.
Amazon Web Services, which helps host much of the content on the web today, also has this registry that helps people find open data hosted on its cloud services. It includes examples of what people have done with that data.
Google hosts the above datasets on BigQuery, its big data storage solution. They include the complete revision history of Wikipedia up to April 2010, and weather information from the NOAA since late 1929.
Data Science Courses/Bootcamps

The curriculum might be a bit too much to handle as a learner — and that’s perfectly fine. It’s meant as a bare-bones categorization of the material you need to learn to get into data science. However, if you want to refine your learning, there are a few options out there. I’ve linked to a list of bootcamps and courses. Be aware that I worked for Springboard.
Data Science Bootcamps
Data Science Bootcamps, CourseReport
CourseReport has a list of different data science bootcamps, with ratings and real student reviews given for each course.
Springboard offers a variety of mentored bootcamps where you’re given personal attention from a data science expert and career coaching. It also comes with a job guarantee. Either get a job or your tuition back once you’re accepted.
Udacity offers nanodegrees where you can dive deep into specific data science topics such as self-driving cars.
Data Science Courses
Coursera offers a variety of online course options for data science. Use them well to deepen your learning in the field.
Udemy offers a variety of data science courses created by different independent teachers on its platform.
Data Science Interview Questions
The data science interview tends to fall into many steps, with some being technical and some being non-technical. I wrote this guide for Springboard on the data science interview process to fully flesh it out. I’ve added some sample questions you might expect, some with solutions, under each section.
Initial Recruiter Call
Before you’re assessed by a hiring manager, you’ll usually have a call with a recruiter to determine if you’re a fit with the company. They’ll ask general questions about your motivations and career path and see if you’re a fit with what the hiring manager wants.
Sample questions
- Why this company?
- What interests you about the role?
- What are your salary expectations?
Technical Interview
A hiring manager will ask you technical questions related to your knowledge of statistics and programming. Here are about 109 data science questions with solutions. For programming, you can try HackerRank challenges as well to stay sharp before your interview.
Technical Case Study
Part of the interview process will involve either an in-depth review of a project you worked on or a case study where you work with your (hopefully) future team. This will involve detailed questions about work you’ve done or how you’d approach a project. You might have to do a take-home assignment or to work on a problem with the hiring manager.
Behavioral Interview
The behavioral part of the interview will test your management and communication skills as well as fit with the team. It’s usually done by the hiring manager rather than the recruiter.
Job Boards And Resources
There are many data science specific job resources and career sites out there worth following. Here are a few where you can find resources and data science job postings.
KDNuggets features a job board and many resources for aspiring data scientists and the community at large.
Kaggle features a host of different resources for data scientists, including datasets that are free and public for use, a customized version of a Python kernel that allows for automated version control as well as collaboration with other Kaggle users and a host of competitions that can help you practice and show your data science skills.
Data Elixir is a newsletter dedicated to data science resources and jobs. Sign up to get a periodical update on the data science ecosystem.
Another great newsletter filled with breaking news and tons of learning opportunities. Data Science Weekly is well worth subscribing to.
Hacker News Jobs is a great spot to cleanly aggregate machine learning and data science job positions from technologists who post on Hacker News “Who’s Hiring?” threads.
What’s great about these postings is that you’ll often find a lot of context and a direct connection to a hiring manager, who will often leave their email directly on a posting to make themselves available for connection. You can easily search for data science specific postings.
AngelList is the world’s largest repository of startups, many of whom are looking to hire for data science roles. You can filter specifically for data science roles, location and industry.
Do You Need A Degree Or Not?
This is an ongoing discussion. Advanced degrees help increase your data science salary and some hiring managers display a bias towards those degrees. Many hiring positions demand a minimum of a bachelor’s degree.
However, DJ Patil, the fromer Chief Data Scientist of the United States, called on recruiters and companies to judge candidates based on what they did with data, not their education.
While the data science community often draws from the same ethos of do-it-yourself learning-by-doing that typifies the open source community, it can be a more gated process because of the statistics and math knowledge needed, as well as the communication skills data scientists need to develop.
Work experience can fill a lot of gaps here, but to get into the industry, it’s possible you might have to start with a data analyst role then move up in a data scientist role, or settle for a junior data science role or internship if you have no experience and no degree.
Despite the emergence of Masters programs targeted for data science, the truth is that you don’t absolutely need a degree to succeed in data science.
Sample Data Science Job Roles

Data Scientist – Personalization @ Spotify
This role at Spotify involves a lot of teamwork and data exploration. It focuses on data modeling. Data engineers help to bring pipelines of data for you to model properly. This role is more focused on the product analytics team, and as a result, is cross-functional in nature. While there is a demand for degrees, most of the other requirements involve applied experience.

Entry Level Data Scientist @ IBM
This entry level role doesn’t need a degree — rather just the skills that make up the data science curriculum. The focus is on communication, tools, and the different models that make up data science roles.
Candid Data Science Career Advice On How To Be A Data Scientist
Here’s some candid career advice from different data scientists in the field to help you with how to be a data scientist:
Claire Longo (Senior Machine Learning Engineer @ Twilio): Beat imposter syndrome by choosing a focus area to master. Talk about the stuff you don’t know as well as the stuff that you do.
Jess Zhang (Inference Data Scientist @ Airbnb): Throw out the first number and do your research when it comes to negotiations. Look through courses and continually refresh and learn so you have a toolbox you can rely on. Find somebody who believes in you, sometimes through networking at data science meetups.
Anmol Rajpurohit (Senior Software Engineer @ Splunk Enterprise Cloud): Data science isn’t for everybody. Make sure you know what you’re getting into before you start a career in data science.
Checklist On How To Be A Data Scientist
1- Learn basic statistics, including frequentist, Bayesian thinking and probability theory.
2- Learn how to programmatically source and organize data, preferably with Python.
3- Learn more the more advanced statistics and mathematics behind data science at scale, from linear algebra, to model evaluation.
4- Practice your learning and work on projects with production-level datasets. Build a portfolio for hiring managers.
5- Prepare for the data science job interview process.
6- Accept a data science job offer (after many months of effort, most likely).
7- Continually practice!







{kind=link}