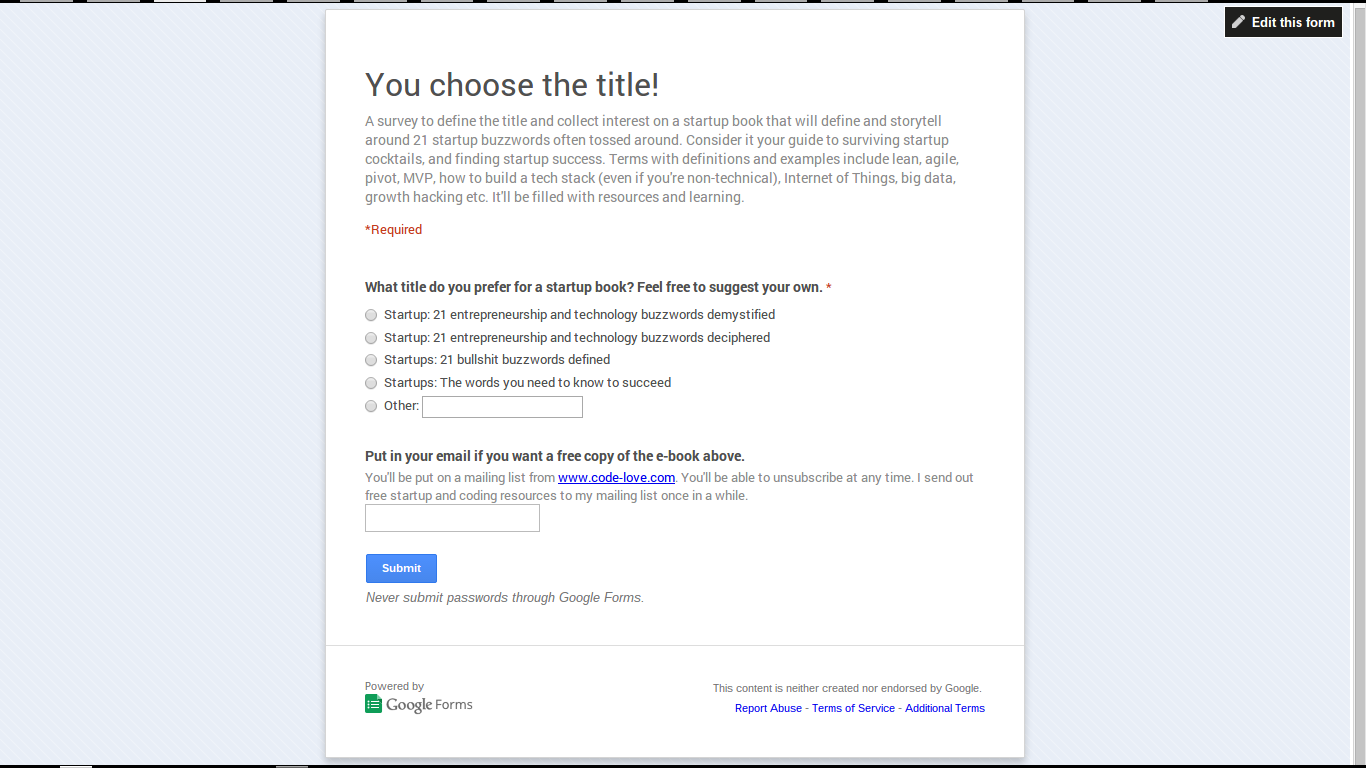
What is growth hacking?
It always helps to have a concrete example. I love learning by doing, so I’ve decided to deep dive into the process for one startup, see what I can learn from it, and share the insights I glean so we can all get a greater understanding of growth hacking. Join me.
![growth hacking with code(love)]()
growth hacking with code(love)
Now, where do we begin?
I like to say that startup growth should be an orchestra: different sections are trying different notes—when you listen to it from the crowd while they’re practicing, you can hear a consonance of some kind, but what’s happening is that each section is practicing how it should tune itself in sync with how the section sounds—and ultimately, how the orchestra itself sounds.
The beauty you hear at the end of a well-practiced orchestra comes from a series of players optimizing for their individual performance, as well as their collective one.
Brian Balfour, VP Growth of Hubspot, nailed it for me: he talks about how the most common question he gets is: what magic growth hack will propel your startup to instant success?
That’s a cop-out.
There’s no single magic bullet. The orchestra can’t just get a superstar violin player that can catapult the whole collective to success: they have to work so that each section of the orchestra gets progressively better, working within their individual units and the whole to deliver incredible, measured results.
There’s no magic bullet to startup growth.
You need a process that takes in new plans, works on existing ones, and gets new and existing players to work together to deliver magic, learning from yesterday’s mistakes to deliver progressively better results, forever experimenting and tinkering to do better.
You need a system to manage that.
For a system you need the aforementioned process, data, creative experiment ideas, and goals to aim for.
For a system you need the aforementioned process, data, creative experiment ideas, and goals to aim for.
I’ve worked with several startups already, but I’ve never had a complete taste of all of the data out there. This has been a function of my location as well as my inclinations: I’m based in Montreal, so I don’t have easy access to all of the startups clustered in major American cities. I’m also inclined towards earlier-stage startups where there isn’t as much data assembled: the startups are still going through the process of learning exactly how to grow. Most of them haven’t had the time to really look back at the data they’ve assembled.
Thankfully, with today’s emphasis on openness, that isn’t a barrier. Taking a page from Ivan Kriemer’s analysis of the Buffer dashboard gave me the inspiration to take a look at Buffer, which has wonderfully made its data and practices available to all.
You might know about Buffer from the great content they put out, not only on their blog, but through the social media management tool that forms the basis of their business. Buffer allows you to queue up a vast array of social media posts: the software handles the optimal timing for everything, allowing you to collect data on the effectiveness and reach of your social media efforts, while reducing the friction of organizing content for those efforts.
They also have a cultural commitment to radical transparency. Buffer has posted employee salaries online, charted their organizational thinking openly, and posted all of their metrics online. All of this leads to a wealth of data to play with.
![Data-driven with code(love)]()
Data-driven with code(love)
Playing with the data yields a whole host of insights. It’ll allow us to come up with experiment ideas, and goals that make sense to “growth hack” systematically, and push Buffer even further into the green.
“[Growth hacking is] experiment-driven marketing.” – Sean Ellis
Caveat here: I might make mistakes in reasoning or gathering numbers here: if I do, I want you to call me out on them in the comments productively. We’re all in here to learn together.
Also, none of this is conclusive because we don’t have all of the data.
It’s very difficult to parse cohort-by-cohort analysis from the open Buffer dashboard, one of the things you should do because each collection of users goes through a different life-cycle of using the product. This incomplete view on the data has a negative effect on any data analysis.
Buffer is a software-as-a-service business, where their users pay monthly for premium features, a typical freemium subscription model. Churn is the enemy of this model. The number of people who jump ship after becoming a subscriber decreases the amount of money you can count on coming in every month.
Most cancellations occur in the first month of a subscription. A churn rate increase, one of the red flags all startups are told to watch for, can be deceptive in this case. You won’t know if it is a function of your product going bad. It could mean that you’re experiencing explosive growth that is driving churn because a larger portion of your userbase are hitting that first month wall with higher cancellation rates. You wouldn’t know if this was the case unless you could measure growth cohort-by-cohort, and separate out old users unhappy with the product, and new ones are just trying it out.
We must also keep in mind that this is insight from Buffer’s Stripe account, which means we’re looking exclusively at when Buffer collects money: that’s fine, but we have no idea of, among other things, when Buffer spends money.
We’d need a look into their Google Analytics/Kissmetrics for that, which means we’re missing at least one essential piece of the SaaS puzzle: cost of acquiring a customer.
The metrics are also anonymized so we have no idea of who the clients are, which helps with privacy issues, but hurts when it comes to making tangible recommendations—beyond hypotheses, assumptions and some aggregated data, we can’t really target great clients based on little more than the revenue categories they’ve been placed in.
Nevertheless, the Buffer dashboard is a great look into one of the fastest growing consumer applications in the world: a set of numbers that implies a lot of activity, and interesting insights to be gained. Finding trends in the data is where all good growth hacking begins, so let’s start.
We have to look at all of the data before we find trends. The current situation looks strong, but there can be improvements. Monthly recurring revenue at $367,000 implying an annual run rate ($367,000 * 12) of $4.4 million (4.404 million to be anatomically precise) means that we’re looking at a business that has hit product-market fit. There are 28,484 current paying customers. Buffer long ago hit the 1 million total user mark: it happened in September 2013, more than a year ago.
In the last Buffer Open update, CEO Joel Gascoigne mentions that there were 1,725,172 total users of Buffer. Extrapolating the average of the two previous monthly growth rates in users (3.3% and 3.7% average to 3.5%)—I’d do a weighted average, but that’s just being pedantic at this point, then you can assume that at mid October, there are now 1,816,800 users assuming a growth rate of 3.5% that takes to us to the end of September, and 1.75% that takes us to the end of October.
![Buffer with code(love)]()
Buffer with code(love)
We now have enough to get almost all of the metrics Kissmetrics considers must-have for SaaS businesses at this stage: monthly recurring revenue, churn, average revenue per user, and the lifetime value of customers. Acquisition cost, as mentioned above, is something we’re going to have to assume.
Important trends from the data
Number of total users (approx): 1,816,800
Number of total paying subscribers: 28,484
Subscription rate (approx): 1.567%
Lincoln Murphy often sees an average 3%-5% conversion rate, but that’s for pure B2B subscription services. For applications with more B2C implications like Dropbox and Evernote, it’s tends to be lower. Phil Libin, for example, structured Evernote to be profitable at a 1% conversion rate. Now, about 2% of all Evernote users are paying customers. Obviously, Buffer would like to do better, but while there is room to improve, this isn’t a bad baseline.
MRR (Monthly Recurring Revenue—the lifeline of a subscription business. How much money keeps on coming in month-by-month: $367,000, growing at a 5.7% clip in the last 30 days.
Joel mentions that August’s 4.8% growth rate was tepid and that he would like to focus on getting it up. The slow growth rate might have to do with the seasonality of the product, given that August is a slow month for social media professionals, an important point to always remember when treating numbers: they always have a greater context. July’s growth was 6.6%.
Getting monthly recurring revenue growth rate up would seem to be a key performance indicator, something important to move the chains on, and measure, because it represents a crucial factor to the health of any business. That’s something we’ll definitely have to consider on our experiment proposals: we’re going to focus more on tasks that are lower in the acquisition funnel, and which deliver money now.
Churn rate (the number of people who are unsubscribing from the service): Monthly user churn: 5.1%, decreasing 5.1% in the last 30 days.
Monthly revenue churn: 6.5%, increasing 2% in the last 30 days.
Seems like good news on the user front, but remember, August was a slower month than most. A churn rate decrease could just be less people hitting that first month wall. A year ago, monthly churn was around 4.4% for context within Buffer. The yearly change in monthly churn rate is 15.8%, a significant uptick.
For context outside of Buffer—70% of SaaS companies had annual churn under 10%. 5-7% annual churn rate is acceptable for pure B2B SaaS companies according to Lincoln Murphy. Again though, Buffer is a strange beast with massive consumer and business applications, more akin to Evernote than any of the SaaS companies incorporated in the survey in the number of people it attracts. Still, a 5.1% monthly churn rate on a purely annualized basis (without taking into account cohort thinking) comes out to 61.2% annual user churn—meaning on an oversimplified basis that Buffer is losing more users than it keeps in a year. It’s something to keep in mind, even if it doesn’t look that bad given Buffer’s expansive user base of millions, and available consumer growth engines: churn rate is pretty high. Getting users might not be as important as keeping them, especially given that it often costs 4 to 6 times more to acquire new users than just to keep existing ones.
How is revenue churn increasing, while user churn is decreasing? Turns out that this a function of Buffer’s split of users into casual and business users, a key insight that will come back again and again.
The vast majority of Buffer users are on the Pro plan, which costs $10/month, or $102/year. This allows you to connect 12 social accounts, and queue 200 posts: basically, if you’re a small business or a freelancer doing social media management, Buffer is reaching out to you. On the other end, there are business plans that can connect hundreds of accounts that will cost you upwards of $250/month.
It appears that monthly user churn of heavy enterprise accounts is really high, a function of the fact that there are so few, and that this seems to be a relatively new cohort. Monthly churn rates for some of these categories are as high as 33.3% (though that seems to me to be a function of the fact that there are so few of these plans). They’re such heavy money earners, even though user churn might be going down as a function of less Pro/Awesome plan members churning, revenue churn can still increase: an important point we’ll return to.
Average Revenue Per User: $13, growing at a 1.7% clip per month.
In a year, this has grown by about 26%, which is relatively static considering monthly recurring revenue has grown by 146% at the same clip. This seems to indicate that the majority of growth is coming from new users rather than finding ways to up-sell current users.
Given that the Awesome/Pro plan is really the only option for consumers, and the rest are billed as business plans, this makes a lot of sense. Upsells would only typically happen if people were transitioning from the Awesome plan to Business plans, suggesting a user behavior pattern of trying the Awesome plan to validate if it can work for a business.
The number of upgrades last year were 3,264, compared to 1,196 downgrades. However, this is somewhat confusing because Buffer counts switches from monthly to annual plans as a downgrade—despite the fact that annual plans actually have a much higher LTV than monthly ones (more on that later). In total, you can surmise that 4,460 people were moving around in the Buffer system last year. Considering that there were 28,424 customers, an oversimplified metric that didn’t account for users doing multiple transitions, and the changing composition of Buffer customers, would indicate that about 15.7% of people move from one tier to another, after only about 1.5% go to being paying customers in the first place. What this means is that people are ready to be upsold, but perhaps Buffer hasn’t captured as much value from that as it should.
Average LTV (Lifetime Value, or how much Buffer gets on average from each client in their full stay with Buffer) of customer: $251, up 7.2% from the last 30 days
This is where Ivan’s analysis of Buffer shines. You realize that there are large LTV values for Enterprise clients but those on the Awesome plan pale in comparison: this is a quantity over quality play, but the contrast is quite stark: $583 LTV for the yearly Pro plan, and merely $134 for the monthly one. This in comparison to the enterprise plans, which often average many times more—some above $25,000 in LTV. You can make a theory that finding ways to commit people to the annual plan will drastically increase MRR, by reducing revenue and user churn.
Given some insight I reached by meeting with Buffer’s COO, Leo, I’ve realized that these are soft-sell clients who have passed the limits of standard plans and asked for custom limits. Given how high the LTV is however, it may well be worth the time to find out how to formalize this arrangement.
My meeting with Leo, COO of Buffer
I managed to snag a meeting with the COO of Buffer, who gave me a lot of insights. I’ve realized that Buffer’s analytics and data are the biggest sell for enterprise clients, that Buffer doesn’t use paid acquisition (doesn’t really work for them) and the biggest growth engines are built into the product itself.
Important insights from the data
Enterprise clients are really important—and it seems Buffer is moving to that direction.
Buffer’s profile is akin to Evernote’s: freemium with a high customer base, and higher adoption rates, but with higher churn rates as a result. Churn can be lowered but it’s not the biggest issue here.
Buffer focuses on its’ content and the product itself as its’ main avenues for growth: and its’ largely working.
Awareness isn’t as much of a problem as activation. The KPI Buffer is really looking for is increasing the monthly recurring revenue.
Buffer is affected by seasonality—it does rise and fall with the whims of its’ power base.
Buffer is seeing a lot of movement between tiers, but maybe not taking full advantage of it.
Experiment ideas
1-Get a contest going: best social media agency, or social media agency with the most clicks gets a free custom enterprise package from Buffer.
This will help spread more awareness of the enterprise options available, and business plans, and will bring out Buffer power users to compete against one another. If you mandate that they have to share their results with the Buffer team, and their tactics, highlighting the agency at the same time—you create a rich slew of content from heavy social media users about some of their tips and tricks.
This will create more awareness about business plans, opening up a new slew of rich, interactive content. Test to see if it is driving more adoption of business plans by linking contest content with sign ups, and tracking to see if this cohort of business sign ups have similar, better or worse metrics than the current average.
2-Create a bigger incentive to sign up for yearly plans.
Add prompts in the upgrade panel about an added benefit—A/B split test to see what works. It could be more posts in the queue,or more social profiles.Offer people who do two months straight an upsell to the yearly plan with an even better discount for being dedicated Buffer members. “Hey, we chose you because you’ve become a Buffer power user, get 20% off our yearly plan!”. Really try to lock people into it.
This should decrease churn, and increase monthly recurring revenue.
3-Post sample case studies of business Buffer analysis and have a Buffer content crafter go over it. Do and don’t of social media. This will highlight the most popular feature of Buffer for Business, and create content that highlights how powerful Buffer’s analytics dashboard truly is.
This should increase activation via signups from the analytics dashboard, and increase awareness of the Buffer for Business rollout.
4-Test a new pricing tier/test pricing
You don’t want to take away from the transition to the business plan, but perhaps a plan that fit in between the Awesome plan and the business plan would work at a flat yearly rate of $200/year. Create a pricing page where you preview a new tier and see how many people sign up, and if people downgrade from a business plan. If the pricing tier makes more MRR, keep it going.
So there you have it: data. A system to manage that data, use it to glean experiments, and measure their effects. If they move the needle, keep the experiments going and scale them. If they don’t, or work against metrics, scrap them.
I hoped you enjoyed this rundown of what growth hacking represents to me. If you want to challenge me on any of my assumptions, or thoughts, please comment below! I know that I don’t know many things, and I am constantly discovering new ways of learning. Please connect with me at [email protected] or at https://twitter.com/rogerh1991 if you want to further the discussion!