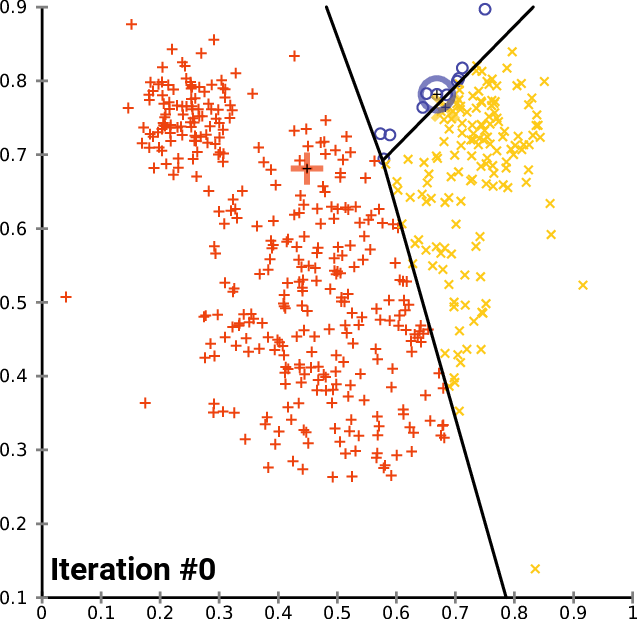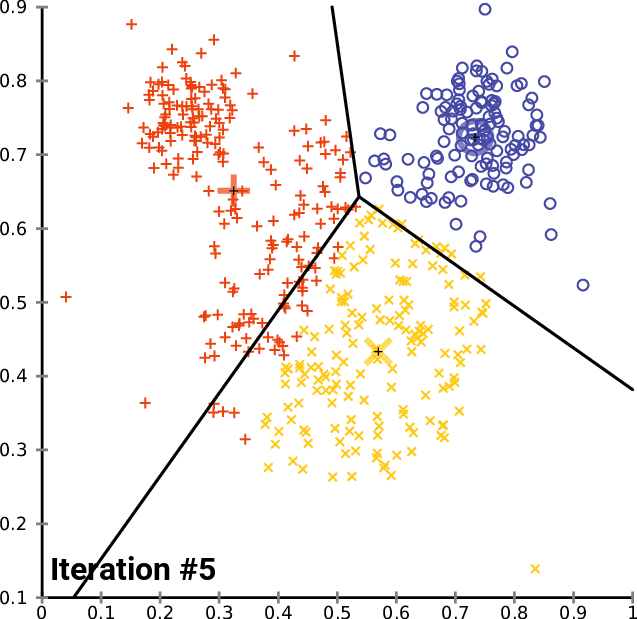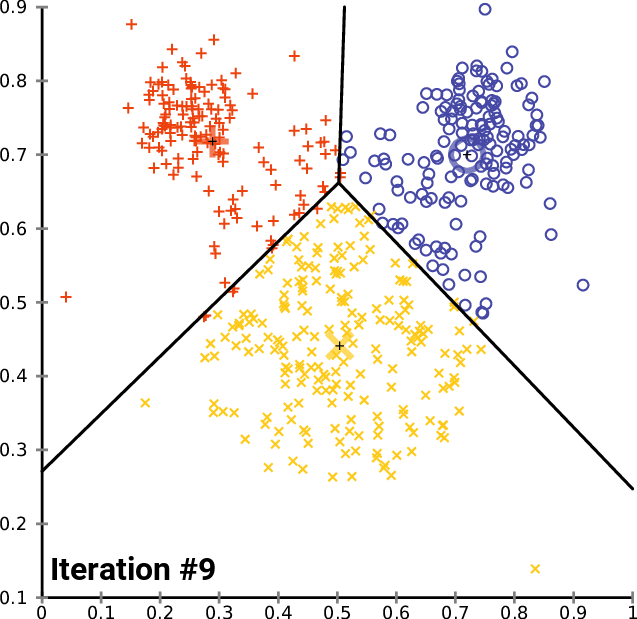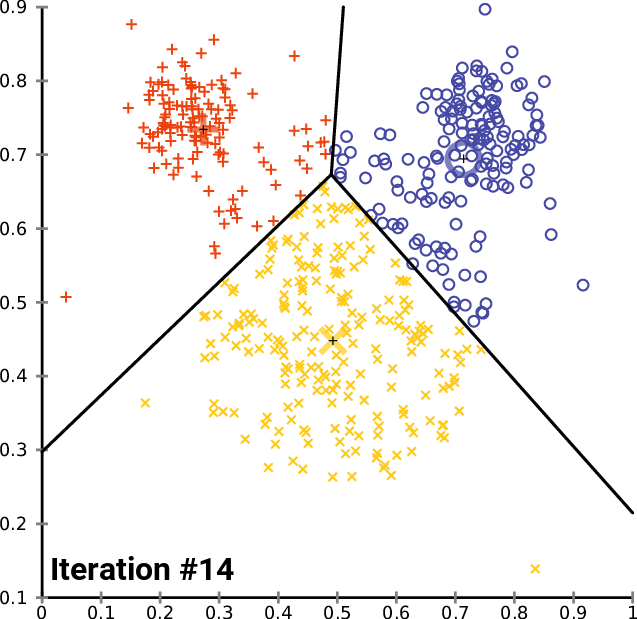
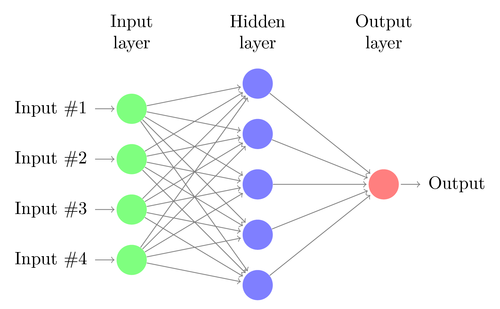
Many people are seeking to learn data science these days. It’s become a trendy topic associated with high salaries and some of the most interesting problems in the world. This demand has created many different resources in the data science space. People have curated their selection of favorite resources to learn data science, but I was seeking out something more comprehensive — so I built this list. Here’s my attempt at getting you my favorite resources in the data science space so you can understand what’s going on in the field — and how you can get your hands dirty and start learning right away.
Full disclosure: I work for Springboard (one of the data science education providers listed below).
What is data science?
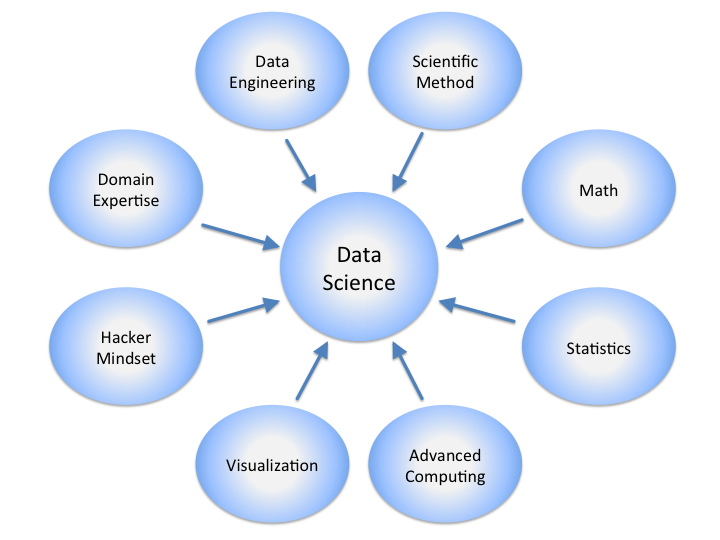
First, let’s start with an overview of what seems to have become a popularized buzzword and defining exactly what you want to learn: data science. Data science is the combination of three kinds of skillsets: statistics, programming and business knowledge. It’s the interplay between these crafts where you’ll find a data scientist — somebody who will programmatically examine large data sets for precious business insights — somebody who can combine computer science knowledge with business insight.
You can use data science concepts and training to do data mining and get statistical inferences from large datasets. Using advanced techniques such as natural language processing and unsupervised learning, you can tame the power of computation and get precious data insights others simply cannot access. That will be attractive to all sorts of potential employers in the data science field, from Silicon Valley to Wall Street.
In order to get there though, you have to start with the basic techniques and basic concepts that underlie data science. Learning data science requires having an understanding of the process that goes behind it, and the various components that are required to bring everything together. Let’s get started on getting you know that knowledge.
Overview

You’ll want to get an overview of the field and the processes and concepts that make up data science so you can learn data science.
1- Data Scientist: The Sexiest Job of the 21st Century
In this seminal article, ex-Chief Data Scientist of the United States, DJ Patil, goes into exactly what makes a career in data science so compelling. It’s great fuel to the fire if you’re looking to learn data science.
2– What is data science?
This overview of data science by Berkeley delves into how data science came to be — and the average salary you can expect in the field.
3– Data Science Salary Survey (2016) – O’Reilly
O’Reilly, a leading publication and media company on the cutting edge of technology, dives deeper into what tools and factors go into higher data science salaries. They’ve surveyed hundreds of data scientists in the field. Learn what pays and what doesn’t with data science careers through their research!
4– Data Science (Wikipedia)
Wikipedia’s overview of data science goes over the history of the field and points to many different resources in the field. It can be a handy jumping-off point for further research.
5– Building Data Science Teams
This piece by DJ Patil goes into the different roles inherent in a data scientist’s job — and exactly how best to build out a data science team.
6- Data Science Process
This piece by Springboard goes into what the day-to-day of data science looks like — tracing it all the way to a first principles view of exactly what steps effective data science requires.
Interactive Tutorials

Now that you’re done with an overview of the topic, it’s time to get your hands a bit dirty with interactive tutorials that will help you learn different parts of data science — whether that’s the statistical theories behind machine learning algorithms, or the programming skills you’ll need to implement those theories.
Statistics/Math
Understanding probability and the basics of statistics is essential to being able to understand machine learning methods and how to handle massive amounts of data. Linear algebra and the ability to manipulate different expressions of data (in matrix form or otherwise) will also be incredibly helpful in detailing what data scientists do. You’ll want to refresh your statistics knowledge and get a handle on the math you need to know to join their ranks.
7– KhanAcademy (Statistics/Probability)
This free course from KhanAcademy serves as a great catch-up on the basics of probability and statistics.
8– Introduction to Statistics in R (Datacamp)
Learn a bit of R (a programming language commonly used in data science) and statistics at the same time with this interactive walkthrough from Datacamp.
9– Statistics 101
This Youtube playlist from the Harvard Extension School covers everything from random variables to different statistical distributions.
SQL
Knowing SQL and how to query from relational databases is a skill that is one of the building blocks of data science. You’ll often use SQL to source your data for further analysis — or even to transform your data on the spot.
10– Mode Analytics SQL School
Mode Analytics teaches SQL through the use of case studies with real data. It’s an interactive experience that’ll teach you the basics of SQL by having you run through a dataset with some simple yet powerful commands.
11– Learn SQL (Codecademy)
Codecademy, well known for its basic curated tutorials in different programming languages, has this simple interactive module that will help you learn SQL.
12– SQLCourse
This is an older tutorial, but one that still holds up as an example of an organized approach to learning SQL.
Python
Python is one of the workhorse languages of data science — one of the most popular along with R. The large open-source community that powers Python enables it to be a powerful, versatile programming language that can help facilitate everything from data wrangling to training powerful machine learning models. It’s a powerful tool you’ll want to learn as you learn data science.
13– Pandas Cookbook
This interactive set of code examples walks you through how to get started with Pandas, the data processing library most commonly used in Python. It’s built by Julia Evans.
14–Intro to Python for Data Science (DataCamp)
This interactive course will walk you through the basics of the data science libraries for Python.
15– Gentle introduction to scikit-learn
This gentle introductory tutorial will help you understand one of the most powerful machine learning and data science libraries out there: Python’s scikit-learn. You’ll be able to train simple, off-the-shelf data models in a matter of minutes.
16– A dramatic tour through Python’s data visualization landscape
This somewhat witty and whimsical walkthrough will help you explore the difference between the major data visualization tools in the Python ecosystem — including some options that were ported from R!
17- Web scraping with BeautifulSoup
This short guide will teach you how to take information from different websites and render it into a format that is easy for machines to process — a handy skill for anybody looking to work with many different datasets. I often use the set of techniques described to scrape tables from Wikipedia so I can process that data in Python.
R
R is another popular programming language used for data science — in fact, it’s often pitted against Python as a comparable tool. The truth is that you can use both — and in fact, being conversant in both can only help you progress faster and further as a data scientist.
18– Introduction to R (Datacamp)
Here is the equivalent of the Datacamp introduction to Python — except this time for R, another common data science programming language.
19– A complete tutorial to learn R from scratch
This tutorial, rendered as a blog post, offers a comprehensive A to Z guide to getting started in R. It covers everything from importing data into R to creating predictive models with it.
20 – Try R
Sponsored by O’Reilly Media, this interactive course will reward you with a badge for each fundamental building block of R you learn.
Hadoop
Hadoop is a big data framework meant to facilitate the treatment and storage of large data sets that have be processed in parallel by many different servers in order to yield actionable insights.
21– Hadoop Tutorial (Tutorialspoint)
This set of tutorials on Hadoop will help you understand how big data frameworks work — and how you can apply Hadoop to your data.
22– Hortonworks Sandbox tutorial on Hadoop
This interactive Hadoop sandbox by Hortonworks lets you play with Hadoop code.
Spark
Spark helps solve some speed, flexibility and efficiency issues with Hadoop through the use of a new data structure: the RDD or resilient distributed dataset.
23– Apache Spark Tutorial (TutorialsPoint)
TutorialsPoint offers a similar tutorial to Spark as it does for Hadoop.
24– Hands-on introduction to Spark
Hortonworks has a sandbox that will let you play around with Spark code.
Courses/Workshops

The following courses and online workshops will help you learn data science in an organized fashion. Use these resources to accelerate your learning of data science if you need to. A lot of these courses will help you find data science work, and you’ll likely be able to do data science projects after finishing them.
25– Fast.ai
This massive online course, built by a Kaggle champion in machine learning, will help you learn about neural networks and how to train machine learning models.
26– Foundations of Data Science (Springboard)
This course offered by Springboard features a curated selection of resources in R, SQL and the basics of machine learning, as well as personalized mentoring from data science experts who work in the field.
27– Data Science Intensive (Springboard)
Yet another course offered by Springboard, though this one is more advanced. Focused on Python and teaching the intricacies of machine learning methods, this course will help you use different machine learning techniques with ease.
28–Data Science Career Track (Springboard)
Springboard’s Data Science Career Track is the first online bootcamp to offer a data science job or your tuition back. With personalized career coaching, mentorship from data scientists and exclusive employer partnerships, Springboard is putting it all on the line to help you get a job in data science.
29– Data Science (Coursera)
Coursera partnered with Johns Hopkins University to deliver this nine-course series on data science, covering everything from tools to advanced machine learning methods.
30– Machine Learning (Coursera)
This curated set of machine learning courses taught by Andrew Ng (the famous Stanford professor who founded Coursera in the first place) is one of the best resources to consult as you start understanding data science.
31– Thinkful Data Science Bootcamp
Thinkful, an online education provider, provides a data science bootcamp that will curate your learning of data science and Python.
32– Intro to Machine Learning (Udacity)
Udacity offers a free mini-course curated by Facebook and Tableau to help guide you through to doing analysis of the Enron email database.
33– Data Science Certificate (Harvard Extension School)
This data science certificate offered by the Harvard Extension School can help you learn data science while getting credits and credibility from one of the leading universities in the world.
34– Statistics with R (Coursera)
This selection of courses created in partnership with Duke University will help you understand basic probability and the use of Bayes’ Rule through the use of R.
35– Data Science (EdX)
This set of curated learning paths in data science can help you get accreditation in the field — if you’re willing to pay for it.
36– Insight Data Science Fellowship
The Insight Data Science Fellowship is a special type of data science education program — it takes talented PhD. students who have already demonstrated technical skills and aptitude, and helps them bridge the gap between academia and industry with a postgraduate fellowship that combines the best of academic rigor with industry knowledge.
37–Data Science (General Assembly)
General Assembly, one of the largest online education providers in the world, offers courses in data science.
38– Galvanize
If you’re looking for an in-person experience to learn data science instead of something online, Galvanize can help. This link leads to the San Francisco experience — however, Galvanize itself is present in many different other cities.
39– Coursereport Data Science Reviews
Here are some reviews of different data science courses in Coursereport — this will allow you to pick and choose between many different options with fair reviews from previous students on display.
40– Switchup Data Science Reviews
Here are some more reviews of different data science courses, this time from Switchup, another course review site.
Books

Oftentimes it’s not a great course that helps you learn the most — it can be one single resource within that course — say a particularly well-written book. This selection of data science books can help you understand data science in detail.
41– Bayesian Methods for Hackers
This book, delivered as an extended Github repository, can help you understand Bayesian inference and how to think about probabilities by working through them in code.
42– Think Stats
This O’Reilly book helps you conceptualize statistical concepts by having you work with them in Python.
43– Think Bayes
This book combines Python programming with Bayesian inference, and can be a handy resource in case the books above aren’t enough.
44– Deep Learning
This free technical book by some of the scions of deep learning and artificial intelligence (Ian Goodfellow, Yoshua Bengio and Aaron Courville) will help you understand exactly how to think about deep learning and neural networks.
45– Learn Python the Hard Way
In case you need a refresher on Python, Learn Python the Hard Way will help you break down exactly what you need to do to master Python. While it focuses on an older version of Python, the first principles taught here can be useful to those looking to freshen up their knowledge of Python — though you shouldn’t become overly dependent on this book as it has quite a rigid philosophy on one particular version of Python.
46– The Data Science Handbook
This Data Science Handbook curates insights from 25 data science leaders and distills what it truly means to work in this exciting new field.
47– Data Science from Scratch
This book from O’Reilly goes into the first principles of data science, looking beyond the programming tools and frameworks.
48– Storytelling with Data
This book will help you visualize insights that you find within your data and teach you how to communicate them effectively so that you can drive impact with your data findings.
49–Exploratory Data Analysis with R
Roger D. Peng, an expert in statistics, has written this book to teach how to look through datasets with the R programming language.
50–Interactive Data Visualization for the Web
This online book will teach you how to use frameworks such as D3.js to make your visualizations fully interactive on the web.
51–Machine Learning Yearning
This book by Andrew Ng, the famous artificial intelligence leader who founded Coursera, is going to be released soon — sign up to get drafts of new chapters as they come in!
Curated Collections

I know you’re looking for curated resources to learn data science. There’s more than just this list right here — and each collection will help you expand your knowledge and collection of great data science resources even further.
52– Awesome Machine Learning
This Github repository follows the “Awesome” method of curating the best resources in a particular space — in this case, all the different resources you’d need to learn machine learning.
53– Awesome Deep Learning Papers
In case you ever wanted to get a handle on the science behind the amazing technology being built out of artificial intelligence, this awesome curation of deep learning papers will help you continually be on top of exciting new developments.
54– Awesome TensorFlow
TensorFlow is an awesome deep learning framework: this Github repository will have everything you need to learn more.
55– Awesome Data Science
This repository is everything it promises: an awesome curation of different data science resources.
56– Data Analysis Learning Path (Springboard)
This learning path curates different resources in an intuitive fashion so that you can learn the data analysis skills required for data science.
57–The Open Source Data Science Masters
This is a curated curriculum of free, open-source resources to learn data science — consider it a masters’ degree for a fraction of the price.
General Resources

58– A visual intro to machine learning
This interactive, visual view of data science in action can help you conceptualize data science, especially if you prefer to learn visually.
59– Deep Learning Review (Nature)
This paper summarizes some of the latest findings in deep learning and artificial intelligence and it is written by one of the founding fathers of modern artificial intelligence research: Geoffrey Hinton.
60– Build a deep learning machine
This fun little tutorial by O’Reilly will teach you how to build a computer that you can use specifically for data science purposes.
61- How can I become a data scientist (Quora)
This Quora thread contains different thoughtful replies on how to become a data scientist — and includes a bevy of free resources to boot!
62– Becoming a Data Scientist
This blog charts the author, Renee, and her path from being a SQL analyst to becoming a full-fledged data scientist.
Career Advice

Becoming a data scientist is now a career path that many envy — however, getting started and placing yourself in a position where you are paid to practice data science doesn’t start and end with technical skills. Here’s a set of resources that will help spell out exactly what you need to do to have a successful data science career.
63– 2015 Data Science Salary Survey (O’Reilly)
This salary survey by O’Reilly was curated from about 600 respondents who divulged their salary and what they did at work. It’s an informative read on what the average salaries are like in data science and what factors or technical skills can either increase your data science salary — or set it on the path to stagnating.
We already highlighted the 2016 survey as part of our general overview of data science, but the 2015 survey will add even more context on how the data science industry works — and how much you should expect to be paid.
64– Guide to Data Science Jobs (Springboard)
This guide to Data Science Jobs by Springboard curates a variety of job seeker and hiring manager stories and seeks to inform you on every element of what it takes to get a data science job: from how to get hiring managers to notice your profile, to advice on what technologies and skills you should practice before doing a data science interview.
65– Guide to Data Science Interviews (Springboard)
This companion guide to the Guide to Data Science Jobs by Springboard runs you through different interview questions and exactly what hiring managers are thinking when they are on the other side of the table. It’s a comprehensive overview of the data science interview process — and it provides you actionable tips on how to ace the data science interview.
66– Getting your first job in data science
This blog post goes over different general tips on how to get that first job in data science.
67– Data Science Career Paths
This blog post by Springboard breaks down the difference between data analysts, data scientists and data engineers.
Datasets

In order to really get started and to learn data science, you have to have datasets to play with. The following resources will link you to different datasets you can experiment with as you’re learning data science techniques and putting them into practice.
68– 19 Free Public Datasets (Springboard)
This curated list of 19 free public datasets will help you get started on your path to learn data science!
69– Kaggle Datasets
This list of datasets curated by Kaggle comes with upvote functionality as well as comments, so you can exactly which datasets are the most exciting — and what work has already been done with them.
70– Reddit Datasets
This subreddit can be a handy way to pick out new datasets, and see some of the most popular ones.
71– Data.world
This new social network has evolved around sharing great datasets and bringing data fans together!
72– Google BigQuery Datasets
Google BigQuery has open-sourced some interesting big data sets–from Reddit comments to Github activity.
73– Quandl
Quandl is a search engine mostly used for financial and economic data. Comb through if you’re looking in that space for data to play with.
74– Public Big Datasets
This curated list of big datasets can help you practice with Hadoop or Spark.
75– Wikipedia dumps
Wikipedia dumps data from its database and makes it free to analyze every so often. Sift through here if you want to query the world’s largest collection of knowledge on your quest to learn data science.
76– Open Street Map
This collection of open-source geographic data extends around the world in its reach!
Resources/Blogs to Follow

You’ll want to keep an eye on different resources and blogs that update frequently as you learn data science. This ensures that you’re always on top of the latest developments — and it can be a stimulating way to keep your data science skills sharp.
77– Top data scientists to follow on Twitter
This is a list of data science influencers you’ll want to consider following to get to know more about the industry.
78– 50 of the best data science blogs
This curated list of data science blogs will help you find the best blogs to follow as you learn data science.
79– Ultimate guide to data science blogs
This larger, extended guide to data science blogs has a lot more entries — feel free to take a look if you feel like you want something comprehensive to digest.
80– KDNuggets
KDNuggets is one of the largest data science communities on the web, and their blog regularly posts interesting data science content.
81– R-bloggers
R Bloggers is a data science blog focused on tutorials to learn R and different resources in the R ecosystem.
82– Dataconomy
Dataconomy focuses on larger trends in data science rather than many technical tutorials. It’s the data science blog with the largest focus on the European data science scene as well.
83– Analytics Vidhya
Analytics Vidhya contains plenty of technical tutorials on many data science topics.
84– Big Data Made Simple
Big Data Made Simple is a relatable blog that conveys different topics in data science in an approachable manner.
85– Yhat blog
The Yhat blog is always filled with interesting tutorials and data science case studies.
86– Machine Learning Mastery
Machine Learning Mastery focuses on the intricacies of machine learning.
87– Learndatasci
Learndatasci is a blog that offers a broad overview of different data science topics.
88– Mastersindatascience
Mastersindatascience is the resource to consult if you wanted to look at paid offerings to learn data science.
Newsletters

If you want regular updates in your inbox on the latest news in data science, there’s no better way to do that than to subscribe to the following data science newsletters.
89 – Data Science Weekly
This weekly newsletter summarizes the latest tutorials and resources in data science. It’s a very useful resource if you’re looking to learn data science.
90– Data Elixir
Another data science newsletter that will keep you informed on the latest happenings in data science.
91– Python Weekly
This weekly Python newsletter curates a selection of the finest Python resources, many of them related to data science.
92– Datafloq
This handy newsletter promises to be a one-stop shop for you when it comes to big data trends.
93- The Analytics Dispatch
Mode Analytics provides a dispatch to keep you informed on all things analytics and BI-related.
94- Postgres Weekly
This Postgres Weekly newsletter keeps you informed on the latest Postgres updates.
95- O’Reilly Data Newsletter
A premium data science newsletter, O’Reilly will often curate the best data science resources that have popped up.
Communities

While newsletters and blogs are great, interactive communities where participants share articles and comment on them together can truly help you entrench your data science knowledge. Here are just a few of those communities where you can learn data science and interact with different data science practitioners.
96– Datatau
Datatau is a sort of Hacker News for data science resources where data science practitioners discuss the latest news and upvote the best articles.
97– Reddit Datascience
This subreddit deals with general data science topics.
98– Reddit Machine Learning
This subreddit deals with more in-depth machine learning materials and discussions.
99– Reddit Deep Learners
This subreddit deals with how to learn artificial intelligence and deep learning.
100– Reddit Data is Beautiful
This subreddit contains impactful data visualizations that are visually appealing — and a true set of examples if you want to display your data in a beautiful manner.
101– Data Science Stack Exchange
This subcomponent of the Stack Exchange network deals with technical questions and solutions in data science.
102– Quora Data Science
This section of Quora is composed of many of the questions posed about data science — it is an awesome resource for those looking to learn data science.
Hopefully the resources above have been helpful for you to learn data science: let me know in the comments below what you think about them or whether you think there are some I missed!