How to learn data science and deep learning in Python
I recently wrote a 80-page guide to how to get a programming job without a degree, curated from my experience helping students do just that at Springboard. This excerpt is a part where I focus on how to learn machine learning in Python.
How to learn machine learning in Python is a very popular topic: with the rise of artificial intelligence, programmers have been able to do everything from beating human masters at Go to replicating human-like speech. At the foundation of this fantastic technological advance are programming and statistics principles you can learn.
Here’s how to learn machine learning in Python:
Sponsored link:
Python Basics

Before you learn how to run, you have to learn how to walk. Most people who start learning machine learning and deep learning come from a programming background: if you do, you can skip this section. However, if you’re new to programming or you’re new to Python, you’ll want to take a look through this section.
Codecademy is an online platform for learning programming, with free interactive courses that encourage you to fully type out your code to solve simple programming problems.
Introduction to Python for Data Science
This interactive Python tutorial is created by Datacamp, and is more suited to introducing how Python basics work in the context of data science.
11 Great Resources to Learn and Work in Python
This list of resources will point you to great ways to immerse yourself in Python learning. It’s a broad list filled with different resources that will help you, no matter your learning style.
These are instructions for installing Jupyter Notebook, an intuitive interface for Python code. You’ll have all of the important Python libraries you need pre-installed and you’ll be easily able to export out and show all of your work in an easy-to-visualize fashion. I strongly suggest that you use Jupyter as your default tool for Python, and the rest of this learning path assumes that you are.
Statistics Basics

In order to learn machine learning in Python, you not only have to learn the programming behind it — you’ll also have to learn statistics. Here are some resources that can help you gain that fundamental knowledge.
Khan Academy, Math, and Statistics
Khan Academy is the largest source of free online education with an array of free video and online courses. This section on Khan Academy will teach you the basic statistics concepts you need to know to understand machine learning, deep learning and more — from mode, median, mean to probability concepts.
Probabilistic Programming & Bayesian Methods for Hackers
This book will delve into Bayesian methods and how to program with probabilities. Combined with your budding knowledge of Python, you’ll be quickly able to reason with different statistical concepts. It’s a book the author gave out for free — and its deeply interactive nature promises to engage you into these new concepts.
Pandas

The main workhorse of data science in Python is the Pandas data science library, an open-source tool that allows for a tabular organization of large datasets and which contains a whole array of functions and tools that can help you with both data organization, manipulation, and visualization. In this section, you’ll be given the resources needed to learn Pandas which will help you to learn machine learning in Python.
Julia Evans, a programmer based in Montreal, has created this simple step-by-step tutorial on how to analyze data in Pandas using noise complaint and bike data. It starts with how to read CSV data into Pandas and goes through how to group data, clean it, and how to parse data.
The official Pandas cookbook involves a number of simple functions that can help you with different datasets and hypothetical transformations you might want to do on your data. Take a look and play with it to extend your knowledge of Pandas.
Data Exploration and Wrangling

Before you can do anything with the data, you’ll want to explore it, and do what is called exploratory data analysis (EDA) — summarize your dataset and get different insights from it so you know where to dig deeper. Fortunately, tools like Pandas are built to give you relevant and surprisingly deep summary insights into your data, allowing you to shape which questions you want to explore next.
By looking through your dataset from afar, you’ll already be able to understand what faults the dataset might have that will keep you from completing your analysis: missing values, wrongly formatted data etc. This is where you can start processing and transforming the data into a form that you want to answer your questions. This is called “data wrangling” — you are cleaning the data and making sure that it is able to answer all of your questions in this step.
Python Exploratory Data Analysis with Pandas
This article from Datacamp goes through all of the nuts and bolts functions you need in order to take a slightly deeper look at your data. It covers topics ranging from summarization of data to understanding how to select certain rows of data. It also goes into basic data wrangling steps such as filling in null values. There are interactive embedded code workspaces so you can play with the code in the article while you are digesting its concepts.
A Comprehensive Introduction to Data Wrangling
This blog article from Springboard is filled with code examples that describe how you can filter data, detect and drop invalid/null values from your dataset, how to group data such that you can perform aggregated analyses on different groups of data (ex: doing an analysis of survival rate on the Titanic by gender or passenger class) and how to handle time series data in Python. Finally, you’ll learn how to export out all of your work in Python so that you and others can play around with it in different file formats such as the Excel-friendly CSV.
This Pandas cheat sheet, hosted on Github, can be an easy, visual way to remember the Pandas functions most essential to data exploration and wrangling. Keep it as a handy reference as you go out and practice some more.
Data Visualization

Data exploration and data visualization work together hand-in-hand. Learning how to visualize data in different plots can be important is seeing underlying trends.
Beginner’s Guide to Matplotlib
This legend of resources on the official matplotlib library (the workhorse library for Python data visualization) will help you understand the theory behind data visualization and how to build basic plots from your data.
The Seaborn library allows people to create intuitive plots that the standard matplotlib library doesn’t cover easily: things like violin plots and box plots. Seaborn comes with very compelling graphics right out of the box.
Introduction to Machine Learning

Machine learning is a set of programming techniques that allow computers to do work that can simulate or augment human cognition without the need to have all parameters or logic explicitly defined.
The following section will delve into how to use machine learning models to create powerful models that can help you do everything from translating human speech to machine code, to beating human grandmasters at complex games such as Go.
It’s important before we get started implementing ideas in code that you understand the fundamentals of machine learning. This section will help you understand how to test your machine learning models, and what statistics you should use to measure your performance. It is an essential cornerstone to your drive to learn machine learning in Python.
A Visual Introduction to Machine Learning
This handy visualization will allow you to understand what machine learning is and the basic mechanisms behind it through a visual display of how machines can classify whether a home is in New York or in San Francisco.
Train/Test Split and Cross-Validation in Python
This article explains why you need to split your dataset into training and test sets and why you need to perform cross-validation in order to avoid either underfitting or overfitting your data. Does that seem like a lot of jargon to you? The article will define all of these different concepts, and show you how to implement them in code.
Sci-kit Learn

Sci-kit learn is the workhorse of machine learning and deep learning in Python, a library that contains standard functions that help you map machine learning algorithms to datasets.
It also has a bunch of functions that will allow you to easily transform your data and split it into training and test sets — a critical part of machine learning. Finally, the library has many tools that can evaluate the performance of your machine learning models and allow you to choose the best for your data.
You’ll want to make sure you know how to effectively use the library if you want to learn machine learning in Python.
A Gentle Introduction to Scikit-Learn
This post introduces a lot of the history and context of the Sci-Kit Learn library and it gives you a list of resources and documentation you can pursue to further your learning and practice with this library.
The official scikit-learn documentation is filled with resources and quick start guides that will help you get started with Scikit-Learn and which will help you entrench your learning.
Regression
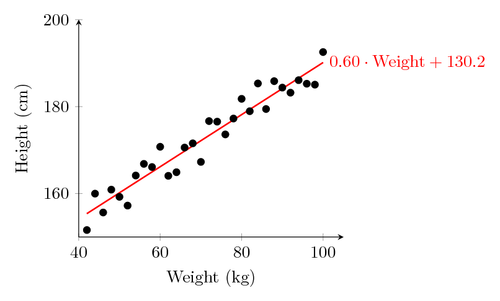
Regression involves a breakdown of how much movement in a trend can be explained by certain variables. You can think about it as plotting a Y or dependent variable versus a slew of X or explanatory variables and determining how much of the movement in Y is dependent on individuals factors of X, and how much is due to statistical noise.
There are two main types of regression that we’re going to talk about here: linear regression and logistic regression. Linear regression measures the amount of variability in a dependent factor based on an explanatory factor: you might, for example, find out that poverty levels explain 40% of the variability in the crime rate. Logistic regression mathematically transforms a level of variability into a binary outcome. In that way, you might classify if a name is most likely to be either male or female. Instead of percentages, logistic regression produces categories.
You’ll want to study both types of regression so you can get the results you need.
Simple and Multiple Linear Regression in Python
This informative Medium piece goes into the theory and statistics behind linear regression, and then describes how to implement it in Sci-Kit Learn.
Building a Logistic Regression in Python, Step-by-Step
This Medium tutorial uses the Sci-Kit Learn tools available to implement a logistic regression model. The amount of detail in each step will help you follow along.
Clustering
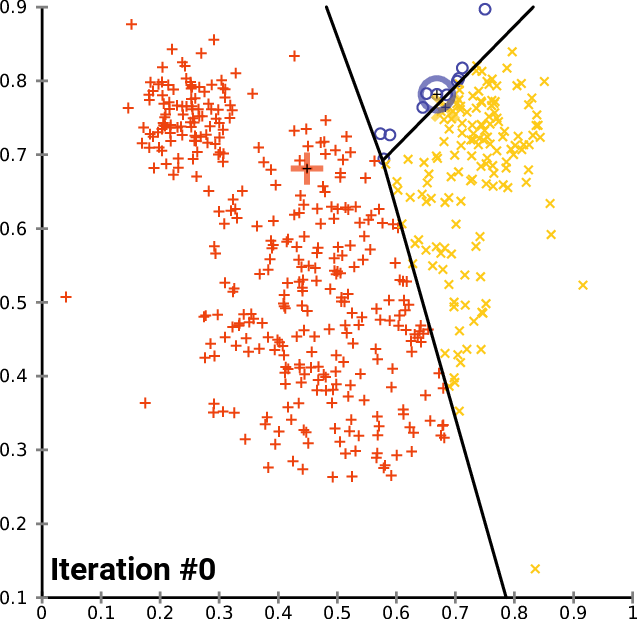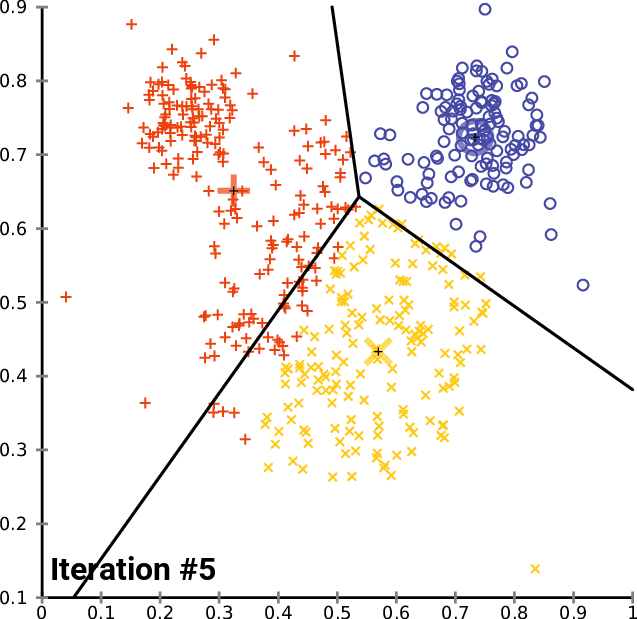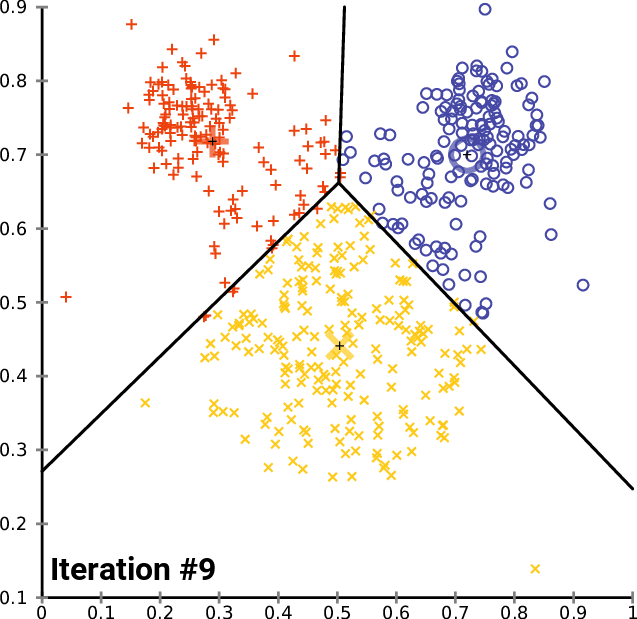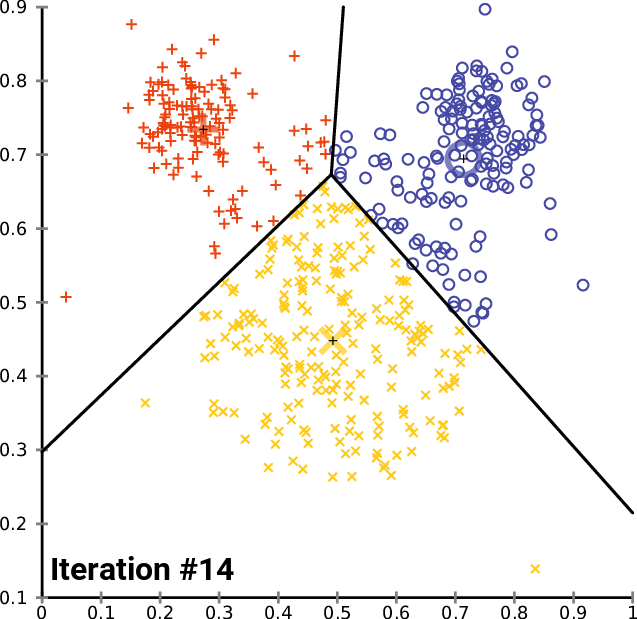
Another type of machine learning model is called clustering. This is where datasets are grouped into different categories of data points based on the proximity between one point and other groups of points. Mastering clustering is an important part of learning machine learning in Python.
An Introduction to Clustering and different methods of clustering
Analytics Vidhya has presented this comprehensive introduction to clustering methods: it’s good to get a handle on this theory before you try implementing it in code.
Customer Segmentation using Python
This article from Yhat demonstrates how to do simple K-means clustering across different wine customers. It’ll take your learning in Pandas and Scikit-Learn and combine them into a useful clustering example.
Deep Learning/Neural Networks
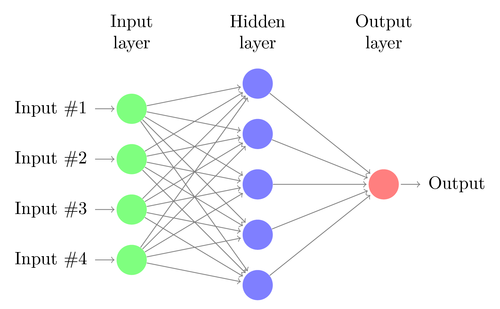
Neural networks are an attempt to simulate how the human mind works (on a very simplified level) in computational code. They have been a great advance in artificial intelligence — and while in some ways they are a black box of complex algorithms working in tandem to learn how data generalizes, their practical applications have exponentially multiplied in the last few years. Deep learning encompasses neural networks as well as other approaches meant to simulate human intelligence. They are an important part to learn if you want to learn machine learning in Python.
In a huge breakthrough, Google’s AI beats a top player at the game of Go
This short Wired article isn’t a technical tutorial: it’s the recounting of an epic match between a human grandmaster at Go, a game that was supposed to be so complex for computers to win that technology to do so wasn’t supposed to come until around the 2030s. By leveraging the power of neural networks, Google was able to bring AI victory forward some two decades or so. This article should give you a great glimpse at the potential and power of neural networks.
A Beginner’s Guide to Neural Networks in Python and SciKit Learn 0.18
This example-laden tutorial uses the neural networks module in the Scikit-Learn library to build a simple neural network that can classify different types of wine. Follow along and play with the code so you can get a feel for how to build neural networks.
Develop Your First Neural Network in Python With Keras Step-By-Step
This tutorial from Machine Learning Mastery uses the Python implementation of the Keras library to build slightly more powerful and intricate neural networks. Keras is a code library built to optimize for speed when it came to experimenting with different deep learning models.
Big Data

Big data involves a lot of volume and velocity of data. It’s an amount of data, measured in petabytes, that can’t be processed easily with tools like Pandas, which are based on the processing power of one laptop or computer.
You’ll want to scale out to controlling many processors and servers and passing data through a network to process data at scale. Tools that allow you to map and reduce data between multiple servers and others such as Spark and Hadoop play an important role here. It’s time to take the learning you’ve had before this and apply it to massive data sets! You can’t learn machine learning in Python without dealing with big data.
Get Started With Pyspark and Jupyter Notebook in 3 Minutes
This blog post will help you get set up with PySpark, a Python library that brings the full power of Spark to you in the Jupyter Notebook format you’ve been used to working in. PySpark can be used to process large datasets that can go all the way to petabytes of data!
This video tutorial will help you get more context about PySpark and will provide sample code for tasks such as doing word counts over a large collection of documents.
Using Jupyter on Apache Spark: Step-by-Step with a Terabyte of Reddit Data
This tutorial from Insight goes a little further than installation instructions and gets you working with Spark on a terabyte (that’s 1024 gigabytes!) of Reddit comment data.
Machine Learning Evaluation
Now that you’ve learned a baseline for all of the theory and code you need to learn machine learning in practice, it’s time to learn what metrics and approaches you can use to evaluate your machine learning models.
Metrics to Evaluate Machine Learning Algorithms in Python
In this tutorial, you’ll learn about the different metrics used to evaluate the performance of different machine learning approaches. You’ll be able to implement them in Scikit-Learn and Jupyter right away!
Model evaluation, model selection, and algorithm selection in machine learning
This long six-part series (check the end of this blog post for more posts after) goes deep into the theory and math behind machine learning evaluation metrics. You’ll come out of the whole thing with a deeper knowledge of how to measure machine learning models and compare them against one another.
Suggested daily routine
Learning isn’t often a static thing. You need ongoing practice to master a skill. Here’s a suggested learning routine you can implement in your day to make sure you practice and expand your knowledge and learn machine learning in Python.
Here’s my suggested daily routine:
- Continue working on something in machine learning at all times
- Go to StackOverflow, ask and answer questions
- Read the latest machine learning papers, try to understand them
- Practice your code whenever you can by looking through Github machine learning repositories
- Do Kaggle competitions so you can extend your learning and practice new machine learning concepts
At the end, you’ll have effectively mastered how to learn machine learning in Python!
Want more material like this? Check out my guide on how to get a programming job without a degree.